The Pancake Stack
At Nitro, we have tried to embrace the idea that simple systems are key to scalable and efficient infrastructure and micro-services and help maximize innovation, velocity, and trust.
If you have not heard this talk by Rich Hickey, please take the time to watch this talk. The points made are invaluable for systems and software development. “Simple” is the opposite of “complex,” which means “being intertwined” or “being tied together.” Simple is not easy, but simple is something to strive for whenever possible. Simple systems are easier to understand and reason about, support and change. If there is one thing we know in this industry, there is always something better coming out, and it can be valuable to replace older components with newer, more simple, more efficient ones. Simple systems are sound and are loosely coupled.
Current infrastructure frameworks and stacks have benefits and drawbacks, and many of them attempt to solve the same functional goals. Our code has a lifecycle: It is built, deployed, tested, and promoted to production; there also needs to exist a mechanism for rolling back versions and killing obsolete or errant tasks. We need a system that can efficiently manage ‘compute’ resources and get our code in front of our customers. The systems and platforms that can serve this lifecycle are generally composed of several components.
-
Compute resources.
-
Resource managers.
-
Schedulers.
-
Service discovery.
-
Load Balancers.
Many stacks that herd these components include Kubernetes, Docker swarm, Mesosphere, Vmware, Rancher, Heroku, and ECS. We decided to take individual application components and create a custom stack as our infrastructure platform. Let us walk through each layer.
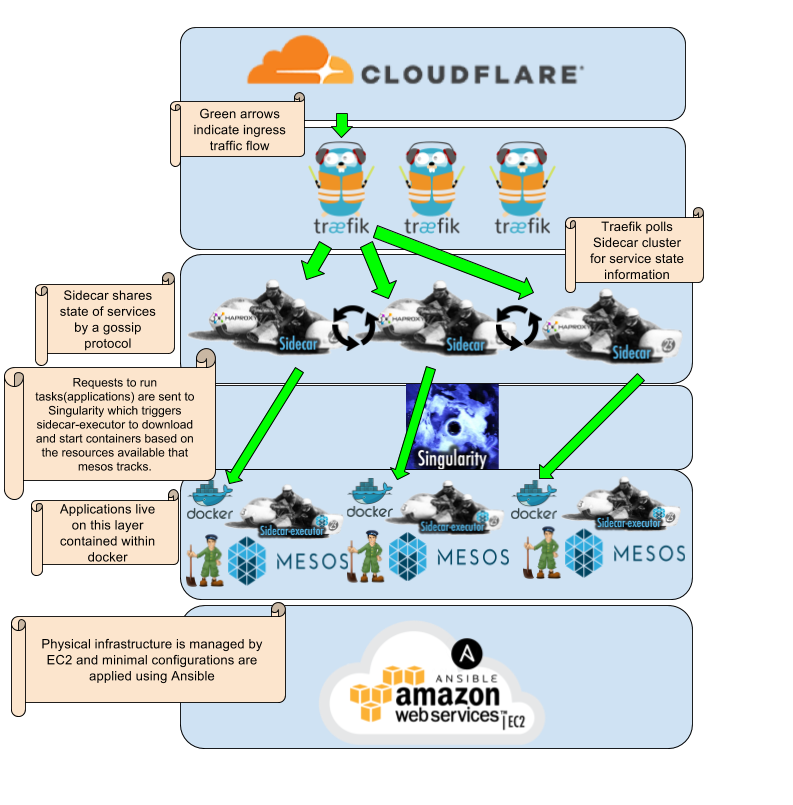
Cloudflare
Cloudflare is the first layer we use, which handles DNS, SSL termination, and DOS protection. In a highly available system there will be multiple ingress endpoints and cloudflare has a nice api that we use for updating dns records in the event that an AWS zone goes unhealthy. We use a tool Ben Parli developed called Goavail. Goavail is a simple IP monitoring and fast DNS failover agent written in Go. More information can be found here.
Traefik
After ingress traffic makes it through Cloudflare, it hits our ingress termination points. We previously had used HAproxy for ingress termination, which was great but moved to a proxy called Traefik. Since schedulers can place tasks on any number of hosts in any part of the infrastructure, there is no guarantee that an app will stay in one place for long, so dynamic service mappings are critical for ingress traffic to get to the right place. Traefik made more sense than haproxy as we wrote a plugin to configure backends using our service discovery tool, Sidecar, automatically. Ingress traffic comes into Traefik, and based on the status of the internal apps, Sidecar lets Traefik know where to send the traffic.
Sidecar / haproxy-api
Sidecar is an eventually consistent service discovery platform where hosts learn about each other’s state’ via a gossip protocol. Hosts exchange messages about which services they are running and which have gone away(tombstoned). Sidecar optionally works alongside the included app called haproxy-api, which takes state information from the Sidecar cluster and updates a locally running copy of haproxy to handle the dynamic port mappings to service ports. All apps are shipped as Docker containers in our environment and Sidecar is designed to work best with Docker. Service names and ports are configured using docker labels which get passed through the system by our deployment tooling Nmesos and singularity/singularity-executor and then to Docker.
Sidecar-executor with Vault, Docker and Nmesos
With Sidecar and Sidecar Executor, you get service health checking unified with service discovery, regardless of which Mesos scheduler is running. The system is entirely scheduler agnostic to the extent possible. We happen to use it with Singularity.
Docker is how we ship our applications. Every application gets delivered as a container that is configured by environment variables. We like to adhere to the 12-factor app manifesto as closely as possible, which reduces friction in our infrastructure and keeps things consistent. Every app is delivered as a container, and each container is configured via environment variables. Scaling is accomplished by adding more concurrent containers using our scheduler(in this case, its Singularity).
Nmesos is a command-line tool that leverages Singularity API to deploy services and schedule jobs in an Apache Mesos cluster.
Sidecar-executor is designed to work with Vault optionally, so secrets are not exposed to the nodes executing deploys or the Singularity API.
Singularity
Singularity is a Scheduler (HTTP API and web app) for running Mesos tasks and keeping track of them. There is not much to explain here other than we use Nmesos, as mentioned above, to send task requests to the Mesos cluster, and Singularity takes care of making sure the right amount of tasks are running at any one time.
Docker
Docker, as mentioned earlier, is how we ship our applications. As well as being the package format of our applications, Docker also takes care of assigning dynamic ports and making sure the networking(at the container level), the volumes(again at the container level), and the security of the container are functioning as defined in the job definition.
Mesos with Zookeeper
Mesos might have one of the most important jobs of all. It keeps track of the resources available and allows tasks to be started in the right places. Apache Mesos abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual). This gives us a pool of resources that can be fully utilized.
Zookeeper allows Mesos to keep track of state across the resources.
Ec2 with Proviso, Ectd and Ansible
We use AWS EC2 because it has a mature API and allows us to scale infrastructure costs as needed. We developed an internal tool called Proviso. We use Proviso to manage our EC2 instances clusters. It stores the cluster state in Etcd, so we can reliably query, provision, and decommission instances. Once a new instance has been provisioned, we use Ansible to run the bootstrap template. This template installs the mandatory packages and sets up the tooling required to monitor the new instance and register it in the Mesos cluster. The bootstrap installs the bare minimum needed tools to get monitoring in place and the Mesos agent running on the machine.
Special shout-outs to:
Ben Parli https://github.com/bparli
Mihai Todor https://github.com/mihaitodor
Felix Borrego https://github.com/felixgborrego
Karl Matthias https://github.com/relistan
In the following articles, I plan to overview the individual software components in more detail with examples.
comments powered by Disqus